Learning to Rank
Unified Off-Policy Learning to Rank: a Reinforcement Learning Perspective (2023)
In this paper, we unified the ranking process under general stochastic click models as a Markov Decision Process (MDP), and the optimal ranking could be learned with offline reinforcement learning (RL) directly.
Our key insight is that the user’s examination and click behavior summarized by click models has a Markov structure … Specifically, the learning to rank problem now can be viewed as an episodic RL problem [45, 1], where each time step corresponds to a ranking position, each action selects a document for the position, and the state captures the user’s examination tendency. … We first construct each logged query and ranking data as an episode of reinforcement learning following the MDP formulation. Our dedicated structure for state representation learning can efficiently capture the dependency information for examination and click generation, e.g. ranking position in PBM and previous documents in CM and DCM. The algorithm jointly learns state representation and optimizes the policy, where any off-the-shelf offline RL algorithm can be applied as a plug-in solver.
I3 Retriever: Incorporating Implicit Interaction in Pre-trained Language Models for Passage Retrieval (CIKM 2023)
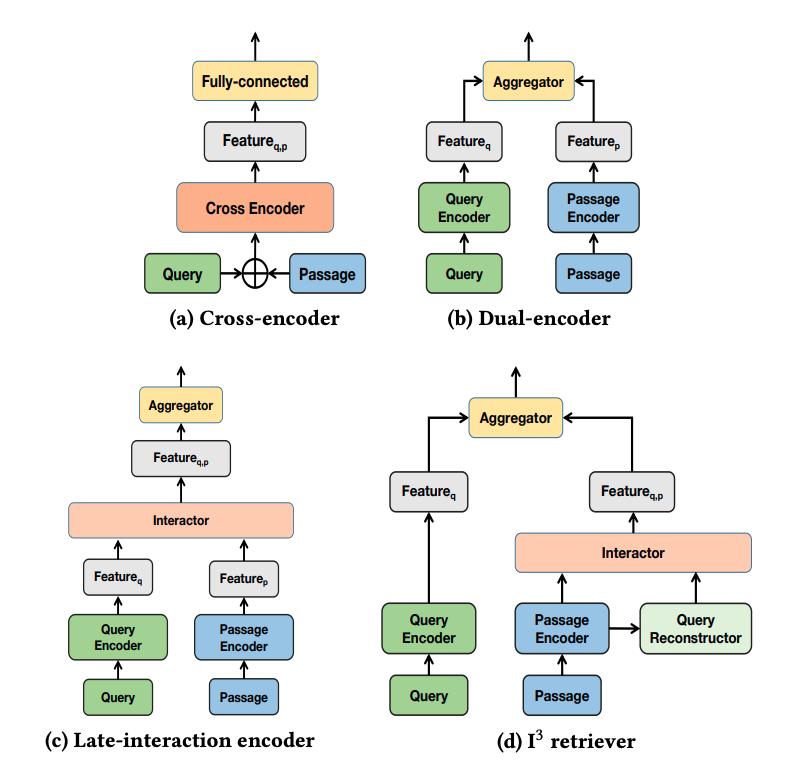
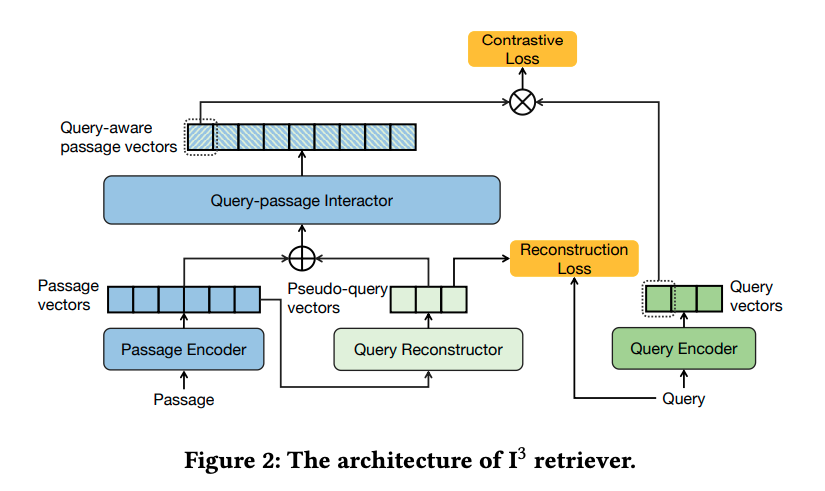
studies have found that the performance of dual-encoders are often limited due to the neglecting of the interaction information between queries and candidate passages. … recent state-of-the-art methods often introduce late-interaction during the model inference process. However, such late-interaction based methods usually bring extensive computation and storage cost on large corpus. … we Incorporate Implicit Interaction into dual-encoders, and propose I 3 retriever. In particular, our implicit interaction paradigm leverages generated pseudo-queries to simulate query-passage interaction, which jointly optimizes with query and passage encoders in an end-to-end manner.
Unlike existing interaction schemes that requires explicit query text as input, the implicit interaction is conducted between a passage and the pseudo-query vectors generated from the passage. Note that the generated pseudo-query vectors are implicit (i.e., latent) without explicit textual interpretation. Such implicit interaction paradigm is appealing, as 1) it is fully decoupled from actual query, and thus allows high online efficiency with offline caching of passage vectors, and 2) compared with using an off-theshelf generative model [41] to explicitly generate textual pseudoquery, our pseudo-query is represented by latent vectors that are jointly optimized with the dual-encoder backbone, which is more expressive for the downstream retrieval task.
Multivariate Representation Learning for Information Retrieval (2023)
Instead of learning a vector for each query and document, our framework learns a multivariate distribution and uses negative multivariate KL divergence to compute the similarity between distributions. For simplicity and efficiency reasons, we assume that the distributions are multivariate normals and then train large language models to produce mean and variance vectors for these distributions.
TBC
Scalable and Effective Generative Information Retrieval (2023)
TBC
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze! (2023)
TBC
Learning to Rank in Generative Retrieval (2023)
LTRGR enables generative retrieval to learn to rank passages directly, optimizing the autoregressive model toward the final passage ranking target via a rank loss. This framework only requires an additional learning-to-rank training phase to enhance current generative retrieval systems and does not add any burden to the inference stage
TBC
Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models (2023)
TBC
LARGE LANGUAGE MODELS ARE EFFECTIVE TEXT RANKERS WITH PAIRWISE RANKING PROMPTING (2023)
TBC
RankingGPT: Empowering Large Language Models in Text Ranking with Progressive Enhancement (2023)
objective of LLMs, which typically centers around next token prediction, and the objective of evaluating query-document relevance. To address this gap and fully leverage LLM potential in text ranking tasks, we propose a progressive multi-stage training strategy. Firstly, we introduce a large-scale weakly supervised dataset of relevance texts to enable the LLMs to acquire the ability to predict relevant tokens without altering their original training objective. Subsequently, we incorporate supervised training to further enhance LLM ranking capability
TBC
Pseudo-Relevance Feedback for Multiple Representation Dense Retrieval (2021)
we conduct the first study into the potential for multiple representation dense retrieval to be enhanced using pseudo-relevance feedback.
in multiple representation dense retrieval – as proposed by ColBERT [16] – each term of the queries and documents is represented by a single embedding. For each query embedding, one per query term, the nearest document token embeddings are identified using an approximate nearest neighbour search, before a final re-scoring to obtain exact relevance estimations.
In this work, we are concerned with applying pseudo-relevance feedback in a multiple representation dense retrieval setting. Indeed, as retrieval uses multiple representations, this allows additional useful embeddings to be appended to the query representation.
ColBERT-PRF applies clustering to the embeddings occurring in the pseudo-relevant set, and then identifies the most discriminative embeddings among the cluster centroids. These centroids are then appended to the embeddings of the original query.
Multi-View Document Representation Learning for Open-Domain Dense Retrieval (2022)
a document can usually answer multiple potential queries from different views. So the single vector representation of a document is hard to match with multi-view queries, and faces a semantic mismatch problem. This paper proposes a multi-view document representation learning framework, aiming to produce multi-view embeddings to represent documents and enforce them to align with different queries.
As for the multi-vector models, cross-encoder architectures perform better by computing deeply-contextualized representations of querydocument pairs, but are computationally expensive and impractical for first-stage large-scale retrieval
So we first modify the bi-encoder architecture, abandon [CLS] token and add multiple [Viewer] tokens to the document input. The representation of the viewers in the last layer is then used as the multi-view representations.
Sparse, Dense, and Attentional Representations for Text Retrieval (2021)
we offer a multi-vector encoding model, which is computationally feasible for retrieval like the dual-encoder architecture and achieves significantly better quality.
A fundamental question is how the capacity of dual encoders varies with the embedding size k.
We therefore propose a new architecture that represents each document as a fixed-size set of m vectors. Relevance scores are computed as the maximum inner product over this set.
We define a single-vector representation of the query x as f (1)(x) = h1(x), and a multi-vector representation of document y as f (m) (y) = [h1(y), . . . , hm(y)], the first m representation vectors for the sequence of tokens in y, with m < T.
Cross-attentional architectures can be viewed as a generalization of the multi-vector model: (1) set m = Tmax (one vector per token); (2) compute one vector per token in the query; (3) allow more expressive aggregation over vectors than the simple maxemployed above.
Rethinking the Role of Token Retrieval in Multi-Vector Retrieval (NeurIPS 2023)
TBC
Black-box Adversarial Attacks against Dense Retrieval Models: A Multi-view Contrastive Learning Method (2023)
Deriving multiple viewers from the initial set of 𝐾 candidates. The key idea is to find several indicative viewers to represent the documents within the initial set … Here, the viewer is defined as a cluster of documents sharing the same topic. … Given a query 𝑞, we first obtain the initial set 𝑅 of 𝐾 candidates … We apply clustering to the representations of 𝐾 candidates to obtain 𝑛 clusters where 𝑛 ≪ 𝐾, and leverage the representation of each centroid as a topical viewer. … To obtain 𝑛 multi-view representations 𝑊 = {𝒘1,𝒘2, . . . ,𝒘𝒏} aligned to viewers, following [5, 6], we encourage the 𝒘𝒊 and its corresponding viewer 𝒗𝒊 to be similar while retaining the original information by minimizing the square loss, … We maintain the distinction between multi-view representations by maximizing the cosine similarity between them
Unsupervised Dense Information Retrieval with Contrastive Learning (2022)
TBC
Questions Are All You Need to Train a Dense Passage Retriever (2023)
TBC
PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval (2024) [Code]
we propose PromptReps, which combines the advantages of both categories: no need for training and the ability to retrieve from the whole corpus. Our method only requires prompts to guide an LLM to generate query and document representations for effective document retrieval. Specifically, we prompt the LLMs to represent a given text using a single word, and then use the last token’s hidden states and the corresponding logits associated to the prediction of the next token to construct a hybrid document retrieval system. The retrieval system harnesses both dense text embedding and sparse bag-of-words representations given by the LLM.
since there could be multiple words to represent the passage, there might be multiple tokens in the vocabulary that have a high probability of being sampled by the language model. Such a distribution over the vocabulary, which often refers to “logits”, could potentially provide a good representation of the given passage. In addition, since the logits are computed by the last layer hidden state2 of the last input token (‘”’), which is a dense vector embedding, it can also serve as a dense representation of the passage.
Sparsification: We retain only the values corresponding to the obtained token IDs in the logits and set the rest of the dimensions to zero, thereby considering only tokens present in the documents. … we only keep tokens within the top 128 values if the logits.
For dense retrieval, we directly use the hidden states as the embedding of the documents. For indexing these embeddings, we simply normalize all the embeddings and add them into an Approximate Nearest search (ANN) vector index.