Other
Neural Networks with Recurrent Generative Feedback (2020)
The Bayesian brain hypothesis states that human brains use an internal generative model to update the posterior beliefs of the sensory input. … . Inspired by such hypothesis, we enforce self-consistency in neural networks by incorporating generative recurrent feedback. … CNN-F shows considerably improved adversarial robustness over conventional feedforward CNNs on standard benchmarks.

TBC
Test-Time Adaptation via Conjugate Pseudo-labels (2022)
TBC
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (2020)
we introduce the linear transformer model … We achieve this by using a kernel-based formulation of self-attention and the associative property of matrix products to calculate the self-attention weigh.
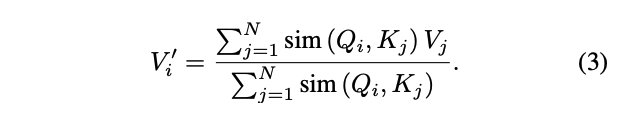
Given such a kernel with a feature representation φ (x) we can rewrite equation 2 as follows,
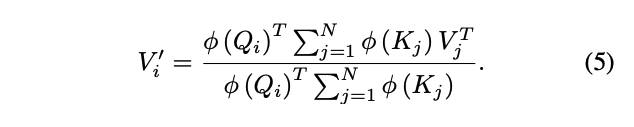
Note that the feature function that corresponds to the exponential kernel is infinite dimensional, which makes the linearization of exact softmax attention infeasible. On the other hand, the polynomial kernel, for example, has an exact finite dimensional feature map and has been shown to work equally well with the exponential or RBF kernel (Tsai et al., 2019). The computational cost for a linearized polynomial transformer of degree 2 is O(ND^2M). This makes the computational complexity. Note that this is true in practice since we want to be able to process sequences with tens of thousands of elements.