Sentence Transformer
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019)
The most commonly used approach is to average the BERT output layer (known as BERT embeddings) or by using the output of the first token (the [CLS] token). As we will show, this common practice yields rather bad sentence embeddings, often worse than averaging GloVe embeddings
SBERT adds a pooling operation to the output of BERT / RoBERTa to derive a fixed sized sentence embedding. We experiment with three pooling strategies: Using the output of the CLS-token, computing the mean of all output vectors (MEANstrategy), and computing a max-over-time of the output vectors (MAX-strategy). The default configuration is MEAN. we create siamese and triplet networks to update the weights such that the produced sentence embeddings are semantically meaningful and can be compared with cosine-similarity
MPNet: Masked and Permuted Pre-training for Language Understanding (2020)
Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for pretraining to address this problem. However, XLNet does not leverage the full position information of a sentence and thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in XLNet).
SimCSE: Simple Contrastive Learning of Sentence Embeddings (2022)
We first describe an unsupervised approach, which takes an input sentence and predicts itself in a contrastive objective, with only standard dropout used as noise. This simple method works surprisingly well, performing on par with previous supervised counterparts. Then, we propose a supervised approach, which incorporates annotated pairs from natural language inference datasets into our contrastive learning framework
Unlike previous work that casts it as a 3-way classification task (entailment, neutral, and contradiction), we leverage the fact that entailment pairs can be naturally used as positive instances. We also find that adding corresponding contradiction pairs as hard negatives further improves performance.
Pooling methods. Reimers and Gurevych (2019); Li et al. (2020) show that taking the average embeddings of pre-trained models (especially from both the first and last layers) leads to better performance than [CLS].
We find that for unsupervised SimCSE, taking [CLS] representation with MLP only during training works the best; for supervised SimCSE, different pooling methods do not matter much. By default, we take [CLS]with MLP (train) for unsupervised SimCSE and [CLS]with MLP for supervised SimCSE.
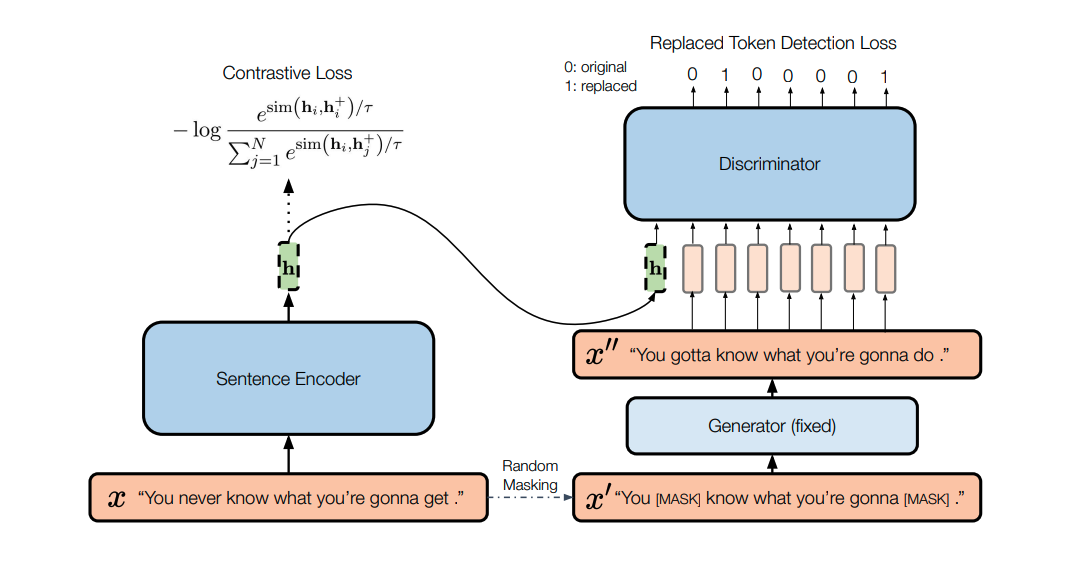
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings (2022)
DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model.
The key observation is that the encoder should be equivariant to MLM-based augmentation instead of being invariant. We can operationalize this by using a conditional discriminator that combines the sentence representation with an edited sentence, and then predicts the difference between the original and edited sentences. This is essentially a conditional version of the ELECTRA model (Clark et al., 2020), which makes the encoder equivariant to MLM by using a binary discriminator which detects whether a token is from the original sentence or from a generator.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT (2023)
TBC
NUGGET: Neural Agglomerative Embeddings of Text (2023)
NUGGET , is an encoding strategy employing hard-attention to map linguistic input into a fractional number of dynamically selected embeddings called nuggets. .. NUGGET leads to an intrinsically interesting representation, where the encoder learns to favor clausal text delimiters, such as punctuation and conjunction words. Moreover, without any explicit guidance during training, each resultant nugget encodes a contiguous segment of text preceding these clausal delimiters
Instead of producing vectors that do not correspond to actual tokens, such as the CLS or averaged pooling over all token embeddings, we leverage the fact that contextual token embeddings carry the semantics of their surrounding texts, and use them as document representations. We use a feedforward network to measure the amount of context information of every token embedding, then select the most informative vectors as the output.
Previous work on the study of transformer language models shows that a large amount of self-attention focuses on the delimiter tokens, such as punctuations, and they may be used as no-op Clark et al. (2019). However, our study suggests that they may also serve as summary tokens, as predicting the end of a segment requires the model to understand the semantics of the preceding texts. It is worth noting that in our case study, NUGGET prefers EOS while BOS is never selected, contrary to the practice of Wang et al. (2021). Also, NUGGET is not necessarily selecting the most frequent tokens